- 링크 : https://arxiv.org/pdf/1905.07129.pdf
- 저자 :Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, Qun Liu
❒ Introduction
- 기존 NLP 모델의 한계점
- BERT를 포함한 NLP 모델들은 단어들의 co-occurrence를 기반으로 단어와 문장의 의미를 이해하는 구조이다.
- 따라서,현실 세계 지식에 기반한 논리적 이해 및 추론 불가능이 불가능하며 동시에 등장하는 경우가 없거나 등장 빈도가 낮은 토큰에 대한 정확한 추론에 한계점이 존재한다.
- 즉, 도메인별 고유명사가 포함된 문장을 이해하고 생성하는데 한계점이 존재한다. - 논문에서 언급한 Bob Dylan 예시
- 아래 그림을 보면 Bob Dylan은 노래 작곡가와 동시에 도서 작가이지만 기존 pretrained language 모델에서는 두 가지 직업의 인식이 어렵다. 특히 노래 이름, 책 이름과 같은 고유명사를 포함한 미세한 관계를 추출하는 것은 거의 불가능하며 'Bob Dylan wrote Blowin' in the Wind in 1962' 라는 문장에 대해 'UNK wrote UNK in UNK'로 인식하게 된다.

- Knowledge Enhanced NLP Model
- 풍부한 지식 정보를 고려하면 언어에 대한 이해가 향상되어 다양한 knowledge-driven applications에 도움이 될 수 있으며,domain-specific한 NLP 테스크 (QA, Entity typing, Relation Classification)에서의 성능 향상이 가능해진다.
- 이에 따라 NLP 모델에서 최고 성능을 보이는 BERT를 기반으로 지식 기반 추론 능력을 부여하고자 ERNIE가 제안되었다.

❒ Architecture

- ERNIE 모델의 아키텍쳐는 위 그림과 같다. 거의 대부분은 BERT와 동일하며 차이점은 각 Encoder가 T-Encoder, K-Encoder 두 가지 모듈로 구성되어 있다는 점이다. T-Encoder는 Textual Encoder로 일반 Transformer 인코더와 동일하다.
- ERNIE의 차별점은 K-Encoder를 통해 Entity input 정보를 활용한다는 점이다. Entity input은 Knowledge graph를 기반으로 TransE와 같은 그래프 임베딩 방법을 활용한다.
- 세부적인 아키텍쳐 설명에 들어가기 전에, KG(Knowledge graph)와 KG embedding에 대한 간단한 내용을 첨부하였다.
✔️ Knowledge Graph
- 객체(Entity)들간의 관계(Relation)가 표현된 유향그래프로서 Node(Entity : 고유명사, 연도, 대표속성등)와 Edge(Relation : 관계)로 구성되어 있다.
- 복잡한 도메인(텍스트, 이미지 등)은 관계형 그래프로 표현할 수 있는 구조를 가지고 있기 때문에, 최근 Graph 기반 딥러닝 방법론이 활발하게 연구 중에 있다(GNN, GCN, GAT 등).

✔️ KG Embedding
- Triplet (head, relation, tail) 으로 구성된 모든 Entity 와 Relation을 벡터로 표현하여, 벡터 연산을 통해 Graph Completion 수행한다.
- 기존 Word2Vec, Glove와 같은 word embedding 방법은 Co-occurence를 기반으로 의미구조를 반영하지만, 지식 그래프 기반 임베딩은 각 entity에 대한 논리구조 유지가 가능하다.
- 대표적인 KG Embedding 방법으로 TransE, TransH, TransR 등 존재하며, 기본적으로 'head + realation = tail' 논리구조를 학습하게 된다. (하단 그림 참조)



K-Encoder
- T-Encoder는 일반 Bert 인코더와 동일하기 때문에 스킵하고, K-Encoder부분 부터 정리해보았다.
- 기본적으로 K-Encoder는 여러층의 aggregator로 구성되어 텍스트로부터 얻은 feature vector와 KG의 entity vector 간의 Heterogeneous information을 Fusion하는 역할을 수행한다.
✔️ Heterogeneous Information Fusion
: External knowledge와 language representation을 결합하여 동일 vector space alignment
① Word Embedding(Token), KG Embedding(Entity)에 대해서 각각 Multiheaded attention을 거친다.
② KG entity와 일치하는 토큰이 있을 경우, 일치하는 토큰과 entity에 대해서만 Self attention 이후 추출된 vector에 각각 weight matmul을 해주며 heterogeneous 정보가 결합된 새로운 inner hidden state가 생성된다. 이 새로운 hidden state는 다시 토큰과 entity에 대해서 linear layer와 activation 을 거치게 된다.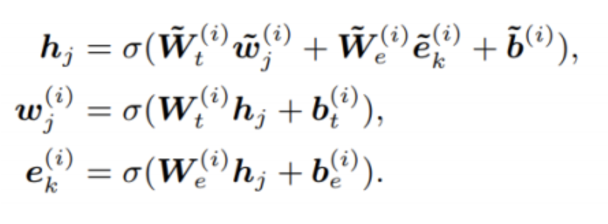
③ KG entity와 일치하는 토큰이 없을 경우에는, 일반적 BERT Layer와 동일한 연산을 거친다.

dEA (denoising entity auto-encoder)
- ERNIE의 주요 challenge였던 Heterogeneous information fusion을 수행하기 위해 윗 단계에서 각 임베딩값을 결합한것과 더불어 dEA라는 새로운 loss function을 추가하였다.
- Entity의 지식을 text representation에 주입하기 위해 token-entity alignments를 무작위로 masking하여, token sequence에 상응하는 entity 예측 성능을 향상시킬 수 있다.
- 5% : 기존 entity를 random entity로 대체
- 15% : token-entity alignments 마스킹
- 나머지 : 유지 - 전체 Pre-training loss : BERT에서 활용한 MLM, NSP에 추가로 dEA까지 함께 활용
→ masked language model (MLM), next sentence prediction (NSP) + denoising entity auto-encoder(dEA)
❒ Evaluation
- Entity Typing (FIGER, Open Entity Dataset)

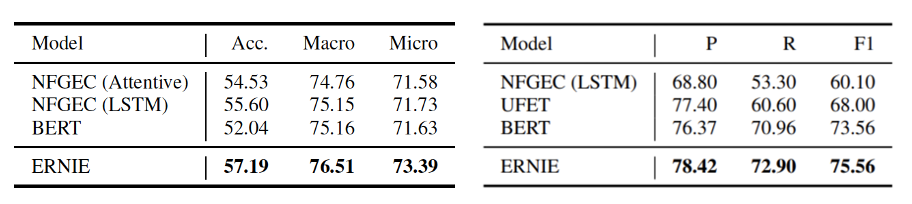
- Relation Classfication (FewRel, TACRED Dataset)


→ External Knowledge Task에 대해서 BERT보다 높은 성능을 보였다.
- GLUE Benchmark Task
- GLUE Task는 외부 지식을 요구하지 않지만, BERT와 유사한 성능을 보였다는 점에서 Heterogeneous information fusion 이후에도 Textual 정보의 손실이 없다는 것을 알 수 있다.
